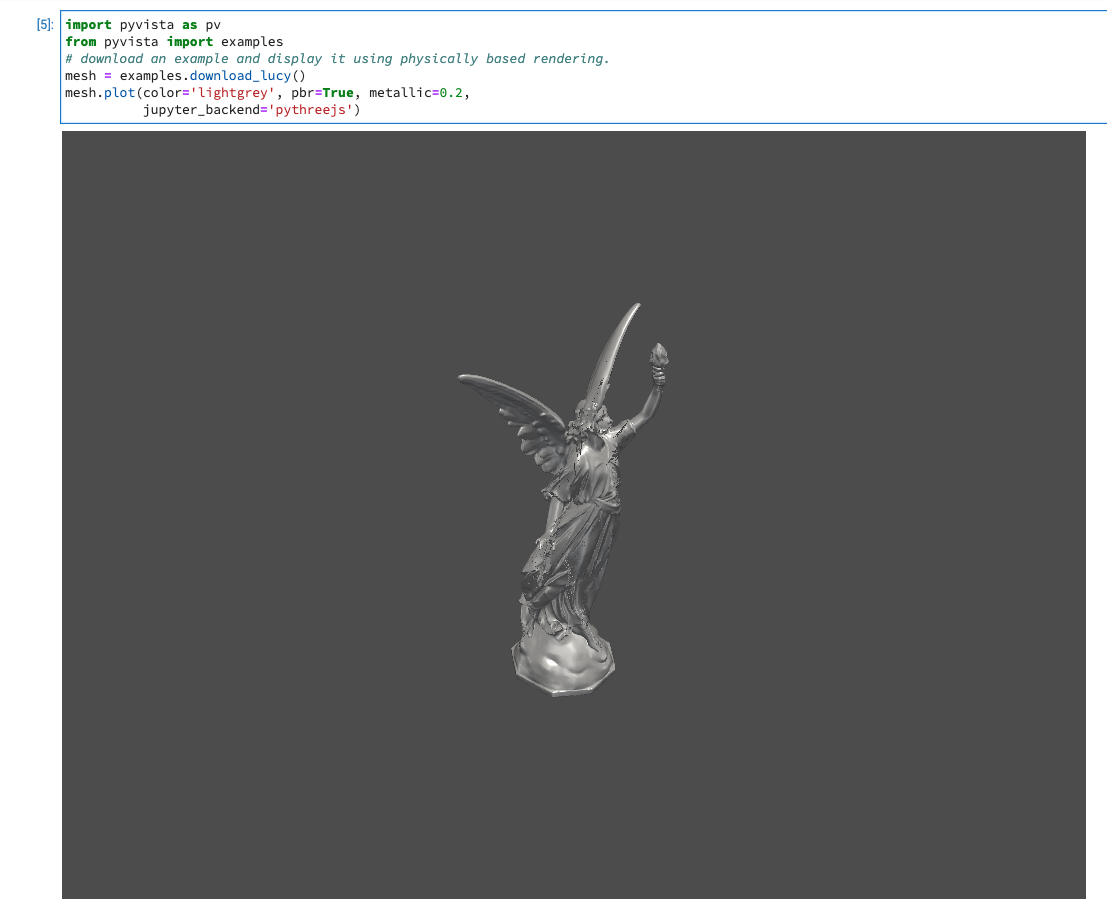
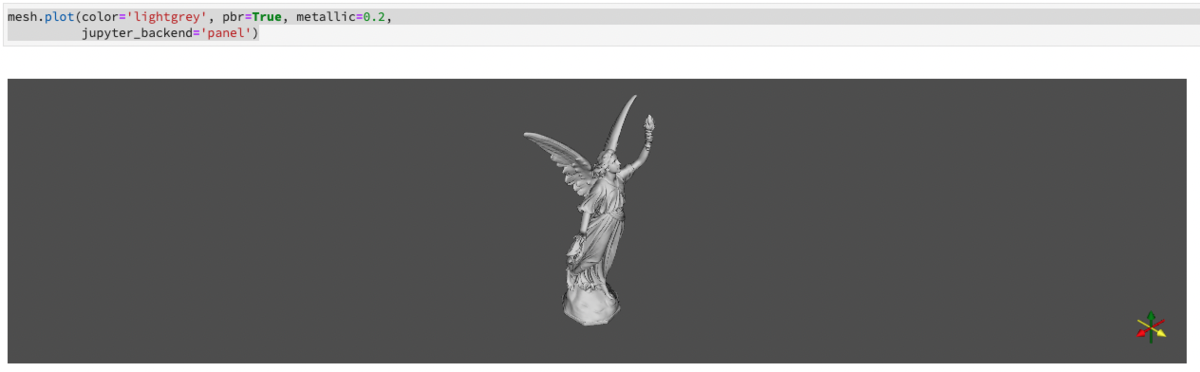
アイワの肩乗せスピーカーButterflyAudioと、Sonyの穴空きイヤフォンLinkBudsを発売直後に買いました。 3ヶ月近く使ってきて、私の中での評価が定まってきたので、これまで使ってきた外音取り込み系イヤフォン&ネックスピーカーと合わせてレビューします。
まずお約束
- 全て私が購入して使用した製品のレビューです。内容は主観的なものなので私個人の好みや体格なども影響しているかもしれません。
- あしかけ4年ほどかけて購入&使用してきたた製品なので、既に生産終了されているものもあります。
- ページ内のamazonへのリンクにはアフィリエイトが含まれています。
レビュー対象(購入順に紹介していきます)
- ソニー ワイヤレスノイズキャンセリングヘッドホン WH-1000XM2
- ambie wireless earcuffs
- earsopen PEACE TW-1
- JVC SP-A7WT-B NAGARAKU ウェアラブルネックスピーカー
- aftershokz(現 shokz) Opencomm
- アイワ ButterflyAudio HPB-SW40
- ソニー LinkBuds
ソニー ワイヤレスノイズキャンセリングヘッドホン WH-1000XM2

good
- ノイズキャンセリング(以下NC)が超強力
- ほとんど締め付け感の無い快適な装着性
bad
- マイクが貧弱
- 外音取り込み機能が使いづらい
私が最初に使った外音取り込み系のデバイスはソニーのワイヤレス密閉型ヘッドホンWH-1000XM2でした。
これを外音取り込み系と言っていいかどうか微妙なとこですが、ヘッドホンの耳の部分に手をあてるとマイク(たぶんNC用のもの)で取り込んだ音をそのまま再生してくれるという機能があります。ただし、新幹線や飛行機で移動中にこのヘッドフォンを使っていると、車内販売の人やCAさんが目の前に来た時に耳に手を合てて外音取り込みモードにしてても「音楽聴いてるっぽいから邪魔しないでおこう」って感じでスルーされるのでこの機能が役に立った記憶はないですw
そんなわけで、このヘッドフォンは外音取り込みヘッドフォンとしての評価はほぼ0点なんですが、個人的には外音取り込み機能の重要性を教えてくれた機種です。
なんと恐しいことに、
夜中にこれつけてYouTubeを見てたら、ベットから落ちて大泣きしてる子どもを抱えた奥様が背後に立ってました・・・o......rz
以来、本当に集中して良い時以外は常に外音取り込み系のヘッドフォン/イヤフォンを使うようになったのでした :p
一応、amazonではこのモデルもまだ買えるようですが、最新の後継機種はこちらです。

covid19のせいで出張の機会が激減し売却してしまいましたが、NCヘッドフォンとしては本当に優秀なので、もし以前のようなペースで出張するようになったら後継機を買おうかと思っています。
ambie wireless earcuffs
good
- 装着しててもほとんど目立たない
bad
- 先端のシリコンパーツが良く落ちる
- 耳に挟む部分が固くて痛い
さて、私が初めて使った、まともな外音取り込み系のイヤフォンはambieのearcuffsです。 残念ながら既に生産終了になってますが、完全ワイヤレスの後継モデルが昨年の夏から販売中のようです。
AM-TW01 WHITE 耳をふさがないイヤホン 完全ワイヤレス")
この機種は超小型のスピーカーを耳に挟んで、耳の穴に向けて指向性を絞って音を送るような形になってます この構造のおかげか、ちょっと大きいイヤフォンくらいのサイズ感で、耳の外につけてる割には存在感がほとんど無いのが良い点でした。
公式サイトには装着して外を走っているイメージ写真が載っていたので、真似してジムで走る時につけて音楽を聴いてたこともあるんですが、ボリューム最大にしても音量が小さめなのでまわりがうるさいとほとんど聴こえなくなります。 また、先端部分のシリコンパーツが取れやすく何度か紛失してしまいました*1
web会議の時にも使ってましたが、耳に挟む部分が狭くて固く1時間も使っていると耳が痛くなってきたのもちょっと辛かったです。
結局、数ヶ月使ってましたが「外音取り込みイヤフォンは良いんだが、こいつとは相性が悪い」という結論になって、次のearsopenが到着した時点で処分してしまいました。
earsopen PEACE TW-1
boco earsopen PEACE TW-1 WHITE PEACETW1WH")
good
- 左右独立の充電ランプ
- (ambieと比較すると)柔らかくて耳にダメージを与えない付けごこち
bad
- ぱっと見で分かるくらい目立つボディサイズ
- バンド部分が折れた
前のambieを使っている頃に、もっと良いのが無いかなぁと探していた時にこれのクラファンをみかけて購入(?)しました。
earsopenもambieと同じように耳に挟むスタイルなんですが、つけごこちは比べものにならないほど柔らかかったです。 さらに、こちらは骨伝導式で位置が多少ずれてても同じように聴こえるので、長時間使う時はつける場所をずらしながら使うという手も使えました。
あと、地味な点ですが、この機種の充電ランプは左右独立していて、個別に充電中かどうかが分かるようになっています。 ケースに戻して充電ランプもついてるので大丈夫と思っていたら片方しか充電できておらず、いざ装着するとバッテリーが切れているという悲しい事故を防げる大変素晴しい機能なんですが、この機種以外では採用されているのを見たことが無いですね。
この機種最大の弱点は、おそらく見た目です。webサイトの写真を見てもらえば分かりますが、ものすごい存在感です。これをつけて仕事してて家族に「何つけとんかと思った」と言われたことは一度や二度ではありません。あと、骨伝導方式のためなのか結構重たくて、つけたまま左右に顔を振ると、耳だけ振られるような感覚がありました。
もう一点、残念なことに耳を挟む部分の柔らかさが災いしたのか、数ヶ月程度の使用で折れてしまいました。*2*3 折れたのに気付いた時は既に次の次に控えているOpencommのクラファンに申し込んでいたので、修理するという発想もなくそのまま廃棄してしまいましたが、もうちょっとサイズが小さければ修理して使い続けていたかもしれません。
そして、そんな後悔とともに生きている私のために後継機種のクラファンが絶賛実施中です。
ぱっと見たところ、前機種の不満がほぼ全て解消されているようなので、とりあえず申し込んでいます。 届いてからのお楽しみですが、出来栄えが良ければ何か書くかもしれません。
JVC SP-A7WT-B NAGARAKU ウェアラブルネックスピーカー

good
- 軽い
bad
- 音だだ漏れ
earsopenが死ぬ前後に、ちょっと発想を変えてネックスピーカーを試してみようと思って買ってみたんですが、これは大失敗でした。 自分が聴きやすい音量に設定すると、隣の部屋に居る家族から「何か音がしよるよ?」と言われるような感じでした。
唯一の利点はもの凄く軽いってことで、朝起きてなんか首に違和感があるなぁと思ったらつけっぱなしだったなんてこともあったくらいです。
aftershokz(現 shokz) Opencomm

good
- 常用できるレベルのマイク
- 骨伝導とは思えないクリアな音質
bad
- ネックバンドが固い
- 持ち運び時のサイズが大きい
ネックスピーカーが期待に反してまるで使いものにならなかったので、しばらくは折れたearsopenをだましだまし使っていたのですが、Opencommを使い始めた瞬間に、ネックスピーカーもearsopenも処分してしまいました。当時は、もうこれ以上は外音取り込み系のは買う必要が無いかと思ってたんですが、そう簡単に沼から抜け出せるわけが無いですね o...rz
Opencommはネックバンド型のイヤフォンですが、耳に入れるのではなく骨伝導式のユニットを耳のちょっと前のところに当てて使います。ブームマイクもついていてしっかり口元で音を拾える形状になっています。 今まで紹介してきた機種ではほとんどマイクが使いものにならなくて、web会議の時は別にマイクを用意してしゃべってましたが、このマイクは優秀です。自分が話しているところを録音したものを聴いてみましたが、クリアに聴こえるし環境音もほとんど拾ってませんでした。
また再生音質も骨伝導式とは思えないくらいクリアに聴こえて、会議などの話し声だけではなく、音楽もそれなりに聴けるレベルです。*4
弱点は、ほぼ物理形状に起因する問題だけなんですが、意外と使い勝手に影響します。まずネックバンド部分にチタンが入っていて見た目よりそうとう固いです。しかもサイズが調整できないので、装着すると後頭部から1,2cm後ろに浮いた状態で使うことになります。この状態で、リラックスして音楽を聴こうと椅子にもたれかかると・・・ヘッドレストに押されてずれますw
また、ネックバンド部が細いこともあって、外出先で使う時などの持ち運びには気を使います。付属品のセミハードケースに入れて持ち運んでましたが、このケースが大きくて結構場所を取ります。防御力は高そうで良いんですけどね。
アイワ ButterflyAudio HPB-SW40
good
- サラウンドスピーカーのような聴き心地
bad
- 重い
- 首を振った時に音像に違和感が生じる
ButterflyAuddioは一応ネックスピーカーに分類されるものなんですが、普通のネックスピーカーはスピーカーを肩に載せた状態で使うのに対して、こちらは肩に載った土台からスピーカーが生えていて耳のすぐ前に設置されるような形になっています。 ヘッドフォンを手でもってちょっと耳から離して聴いてるような状態で、独特な聴きごこちを感じられます。
音質は別格で、この記事に上げている他の機種では比べものになりません。(というか、うちにあるスピーカーも含めた全てのデバイスの中で一番良いです)
上には弱点として「重い」と書きましたが、正確には重量バランスが悪いと言うべきかもしれません。重心が上寄りな上に首にかける土台部分が円柱状になっているため、ちょっと体を揺らすと本体が揺れて実際の重さ以上に重みを感じます。 あと、耳とスピーカー部の距離がシビアなので、首を傾けただけで左右のバランスが崩れます。映画とかを見てる時は特に気になりませんが、音楽を聴いてる時は違和感が大きいです。でも、実際のところこれを使う時は(重量バランスの問題もあって)椅子にがっつりともたれているので慣れてきた今となっては大きな問題ではなくなってきました。
ソニー LinkBuds

good
- 自然な外音
- 音質が良い
bad
- スピークtoチャットを有効にすると、独り言に反応して再生が止まる
- バッテリーが持たない
最後に紹介するのはSonyのLinkBudsです。一般的なイヤフォンみたいなサイズですが、耳に入れる部分がドーナツ状になっていて、耳に蓋をするような形で装着すると中心部の穴を通って外部の音が聴こえてくるという仕組みです。聴こえ方はambieと似たような感じで再生される音と外音が自然にミックスされて聴こえてくるので、これで何か聴きながら目の前の人と会話すると「自分が聴いているものが相手に聴こえていない」ということに違和感を覚えるくらい自然に聴こえてきます。
今のところ、これをメインで使っていますが、装着時の違和感が少なく、長時間使っていてもほとんど痛くなりません。*5
マイクも、耳のそばで集音しているわりには明瞭で、これまでweb会議等で使ってきましたが相手から聞き返されるようなこともなく問題無く使えています。
さらに、360 reality audioにも対応しているので、アプリとスマホなどを設定するとなかなか面白いサラウンド体験ができます。 対応曲の中でもサラウンド感が強いものや弱いものがあるので当たりを引ければ楽しめそうです。*6
イヤフォンとしての性能は非常に優秀なんですが、残念ながらバッテリーの持ちが悪くて3〜4時間しか持たないので、 終日の会議に参加する時なんかは注意が必要です。充電ケースだけで2、3回はフルに充電できるはずなので片耳づつ充電しながら使えれば問題無かったんですが、残念ながら右耳を充電すると電源がOFFになるのでこの手は使えませんでした。
あと、スピークtoチャットという自分が話し始めたら一時停止してくれる機能がついているのですが、これが独り言にも反応してしまうので私の場合は使いものになりませんでしたw
まとめ
音質やマイク品質だけを考えると、LinkBudsで全てをまかなえそうなデキなんですが、これ一本に絞るためには最低2倍、できれば3倍はバッテリーが持たないと厳しいところです。仕方がないので、今のところはLinkBudsをメインに使いつつ長時間の会議の時はOpencommを、音楽を聴いたり動画を見て遊んでる時はButterflyAudioを使うという形で使いわけています。
この記事を書いてるうちに、LinkBudsをもう1台買って、交互に充電しながら使うのが私には一番良さそうな気がしてきてますが、earsopenの後継機種をクラファンで支援しているので、これが届いてからまた考えるつもりです。